Firmware Scraper
The included scraper is also an important component of the project. Once the Docker containers are built and running, it will start to automatically download and save firmware images from the vendor websites. After that, the downloaded images can be used by the jobs to run tests.
The scraper uses the framework Scrapy to access the download pages of the different vendors and scrape the needed metadata.
After the init script (init_script.sh on Linux, init_script_windows.ps1 on Windows) has been executed, the vendors to be scraped can be configured in the file config.json by setting the corresponding boolean value.
The firmware images shown in the web frontend are not necessarily already downloaded. The web frontend only shows the entries in the database regardless of them being downloaded or not.
Depending on how many images need to be downloaded, it could take some time until the scraper is completely done. Please also keep in mind that this will use a lot of disk space.
To check on the status of the scraper execute the following command in a console:
docker logs --follow scraper
Components
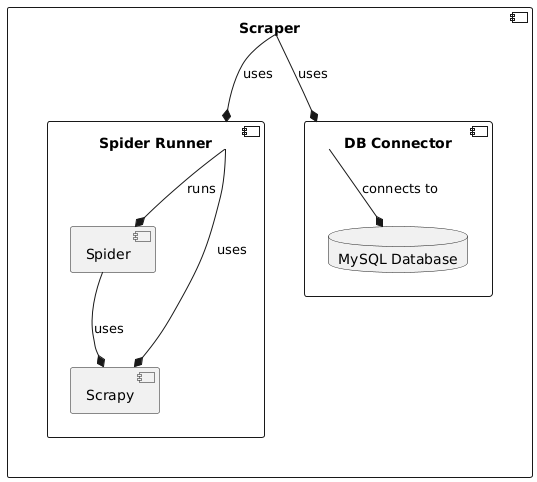
The Firmware Scraper consists of the following components:
Scraper
The Scraper itself orchestrates the scraping process. It does that by utilizing the SpiderRunner to execute the Spiders to scrape metadata from vendor websites while it also interacts with the DBConnector to store and manage the scraped data in the database.
Spider Runner
The SpiderRunner executes the individual spiders that do the actual scraping. It uses the Scrapy framework to start all individual spiders and retrieve the scraped metadata.
Spiders
The spiders are the components that are responsible for the actual scraping of metadata. They are executed by the SpiderRunner and send the scraped items to the SpiderRunner for collection. Since every vendor website has an own layout and works differently, each spider is designed for a specific vendor.
Additional spiders can also be designed to scrape images from vendors that are not yet supported. For information on writing own spiders, see the chapter Write Own Spiders.
To configure which spiders will be executed, adjust the settings in firmware_scraper/config.json.
DB Connector
The DB Connector provides the interface to interact with the database that holds all the information about the scraped firmware images. It offers convenient methods that can be used to execute SQL transactions on the database. It is used by the Scraper to store and manage the scraped data in the database.
It offers methods to create and drop tables, insert products, compare products between tables or set file paths.
MySQL Database
The database holds all information about the firmware images. It is used by the Scraper and the DBConnector to store and manage the scraped data.
The metadata extracted by the spiders and saved to the database contains the following information:
- manufacturer / vendor name: The name of the vendor that produced the firmware (e.g. AVM, Belkin, TP-Link,...).
- product_name: The name of the product, the firmware was produced for.
- product_type: The type of product the firmware is made for.
- version: The version number of the firmware.
- release_date: The date when this version of the firmware was released.
- checksum_scraped: A checksum to validate the downloaded image.
Information is only added to the database if it is available. If the scraper could not retrieve the desired information from the vendor website, for example the checksum, it will remain NULL in the database.
After the images are downloaded, the following information will be added to the entries:
- original_dl_file_path: The path to the file that was downloaded using the provided download link.
- file_path: Since some downloads contain an archive file, this path will contain the extracted actual firmware images.
Scraping Process
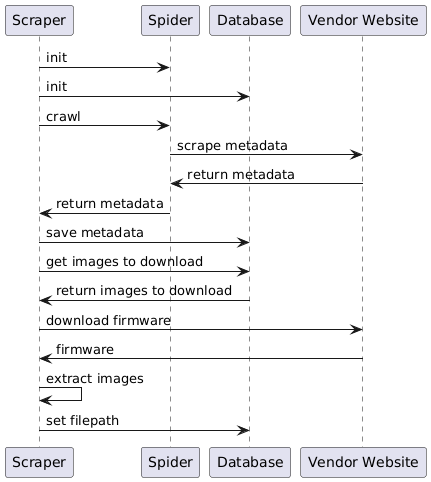
When the scraper starts, it follows a certain process chain:
- The scraper initializes the Spiders and the Database
- The spiders scrape the metadata about firmware images from the vendor websites
- It is checked if the scraped metadata already exists in the database and if not, it will be added.
- After all spiders are done scraping the websites, it is checked which firmware images are not yet downloaded. Those images are then downloaded.
- If the downloaded files are compressed in an archive like a zip file, they are extracted.
- After the desired firmware images are saved, the filepath is added to the corresponding entry in the database so the frontend and the job services can find the actual image files.