How the Executor works
The following section provides a detailed overview of how an analysis job is processed by the Executor in the backend. This is illustrated using a specific example that covers the most important points. The aim is to provide future developers with a rough overview that will help them understand and therefore assist future extensions of the Executor. The following explanation refers to the Python file /jobs/executor/executor.py, which controls the coordination and processing of analysis jobs.
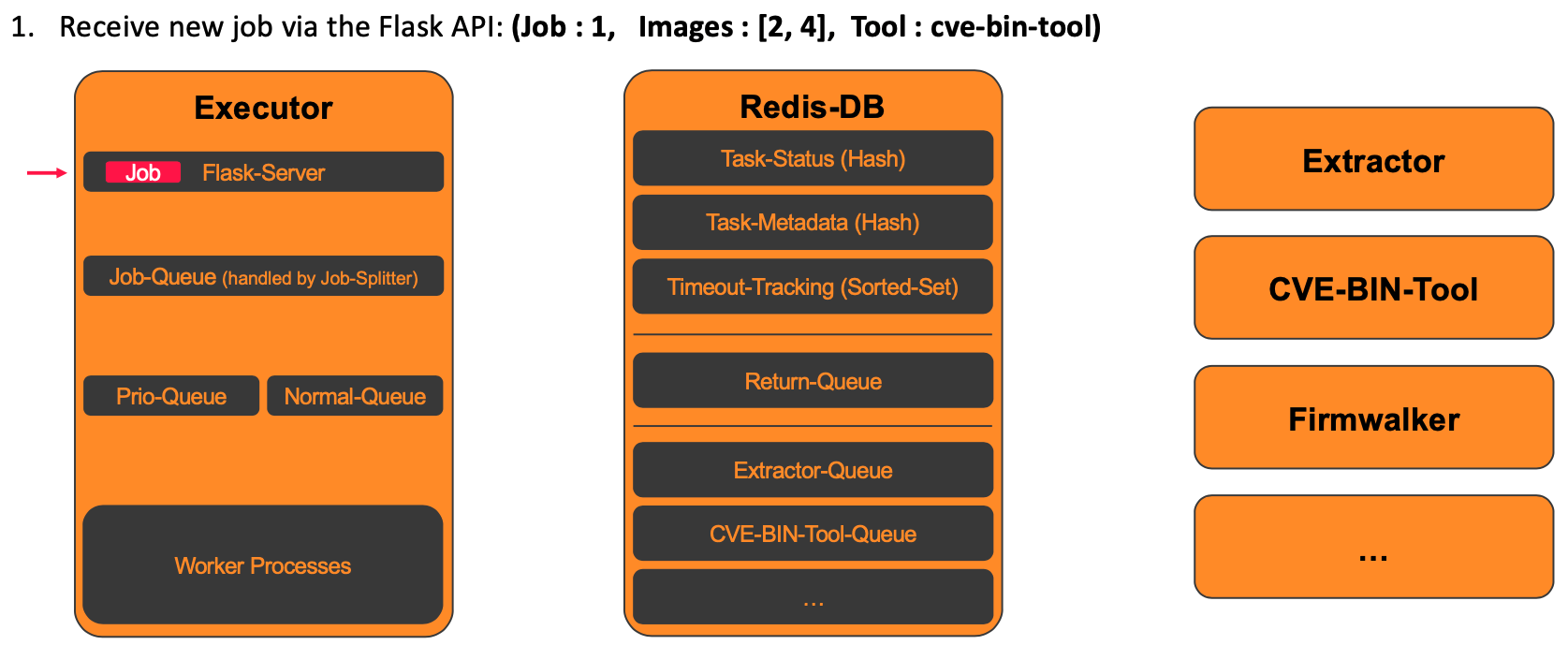
1. Receiving a new analysis job
The processing of a new analysis job in the backend begins when the job is received. The Executor provides a Flask API (/add_job) with which new jobs can be received. The new job is then saved in the job_queue.
2. Splitting the job into tasks
In the next step, the previously received analysis job is split into individual tasks. A dedicated task is created for each firmware image to be analyzed. The splitting is performed by the job_splitter() function, which also creates an initial entry in the database for each task. Finally, all tasks are added to either the prio_queue (for one-time execution) or the regular_queue (for scheduled jobs).
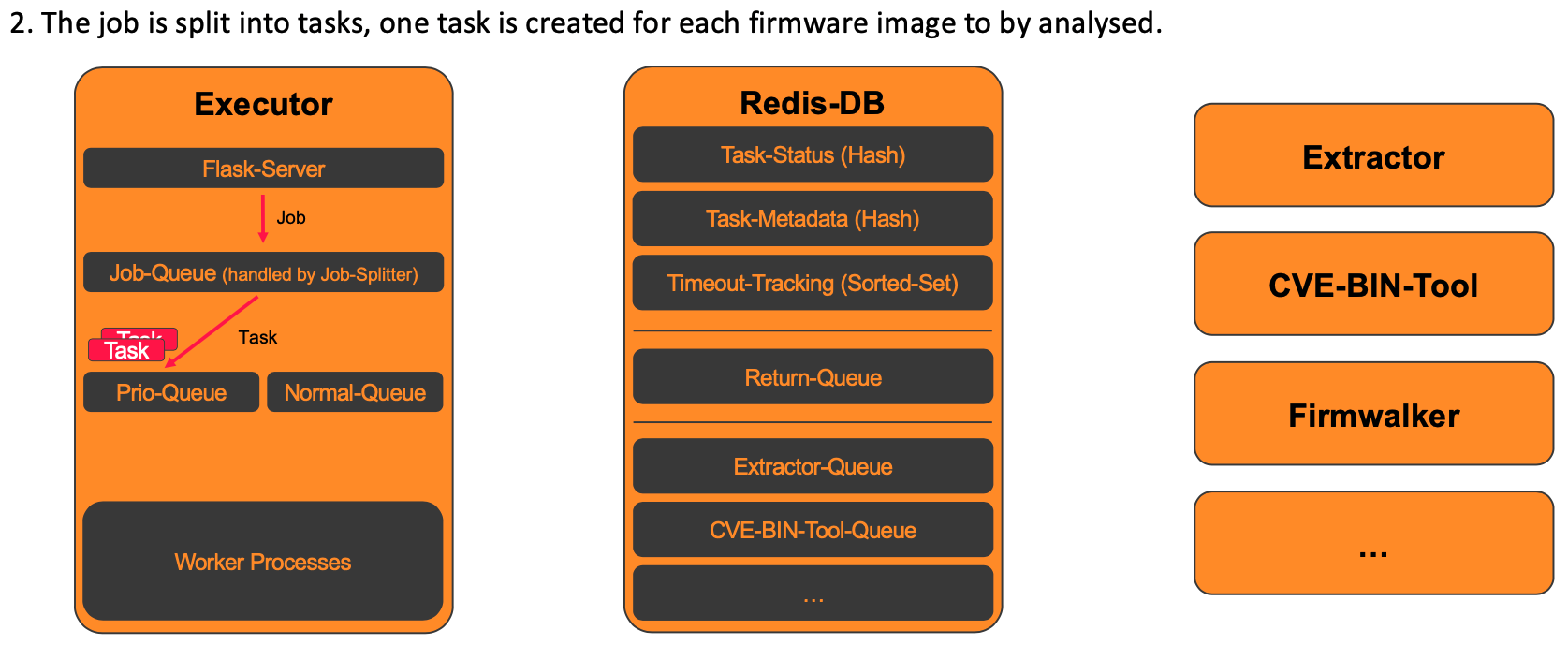
For the example shown, where in the first step the job with ID 1 was received for the analysis of firmware images 2 and 4 with CVE-BIN-Tool, this results in the following two tasks being created.
- Task1: (task_id : 1, job_id : 1, image_id = 2, tool : cve-bin-tool)
- Task2: (task_id : 2, job_id : 1, image_id = 4, tool : cve-bin-tool)
3. Processing of the individual analysis tasks
The Executor's two worker processes running in parallel constantly check whether new tasks are available for processing in the two previously mentioned queues. This is done using the Python code shown below. Care is taken to ensure that no more than two tasks are processed at the same time, as the hardware requirements of some analyses can otherwise lead to unwanted timeouts. If fewer than two tasks are active, the next task is loaded from the queues and processed.
####################################
######## 2. Prio Normal-Q's ########
####################################
else:
# Control the number of parallel tasks to avoid timeouts caused by too many tasks running in parallel.
if redis_task_tracker.get_number_of_active_tasks() >= 2:
time.sleep(15)
continue
try:
next_task : Task = prio_queue.get(timeout=0.5)
except QueueEmptyError:
try:
next_task : Task = regular_queue.get(timeout=0.5)
except QueueEmptyError:
continue
print(f"[Worker] Receive a new task: {next_task}", flush=True)
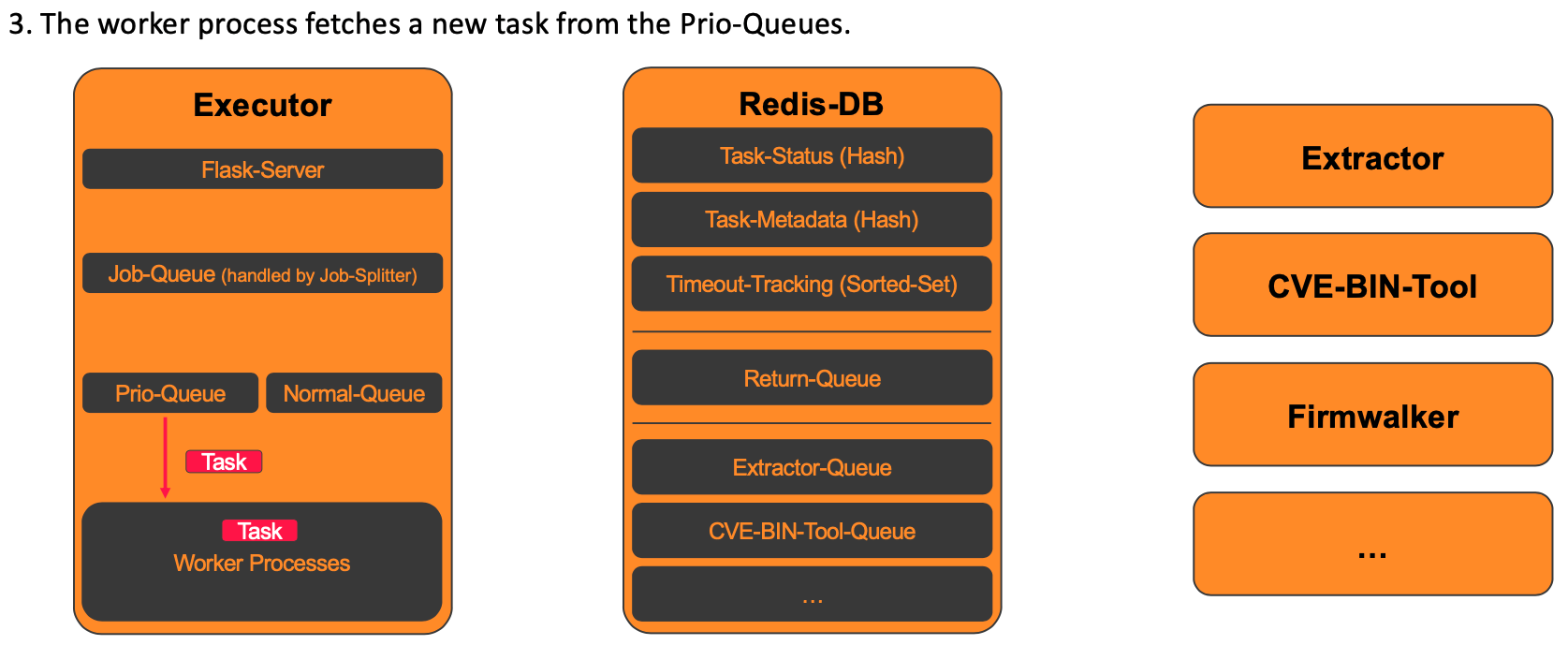
In our example, Task1 would first be loaded from the prio_queue by one of the worker processes, as shown in the following figure.
4. Determine the tool's dependencies
In order to ensure a successful analysis with the selected tools, the Executor resolves possible dependencies between the individual analysis tools in the next step. To do this, the dependencies dictionary is used to determine whether and which dependencies exist for each tool.
dependencies = {
"binwalk" : None,
"cve-bin-tool" : ["binwalk"],
"firmwalker" : ["binwalk"]
}
...
tools = next_task.command
tools = tools.split(" ")
output_path = get_output_path(next_task)
# Resolves the dependencies of the analysis-tools
print(f"[Executor] Tools at the beginning: {tools}", flush=True)
for tool in tools:
if dependencies[tool] is not None:
for dependency in dependencies[tool]:
if dependency not in tools:
tools.append(dependency)
print(f"[Executor] Tools with their dependencies: {tools}", flush=True)
In the example of Task1, in which CVE-Bin-Tool is to be executed on firmware image 2, there is a dependency on the extractor. The firmware must first be unpacked before it can then be analysed with the CVE-Bin-Tool. The exteactor is therefore added as an additional tool for this task in this step.
- Task1: (task_id : 1, job_id : 1, image_id = 2, tool : cve-bin-tool, extractor)
5. Create task in Redis and start the tools without dependencies
In the next step, the entries for the task to be executed are created in Redis. In addition to the status of the individual analysis tools, a sorted set is also created for timeout tracking. The system then checks which of the tools to be executed have no dependencies so that they can be executed first. The corresponding jobs are then pushed into the Redis queues of the respective analysis tools.
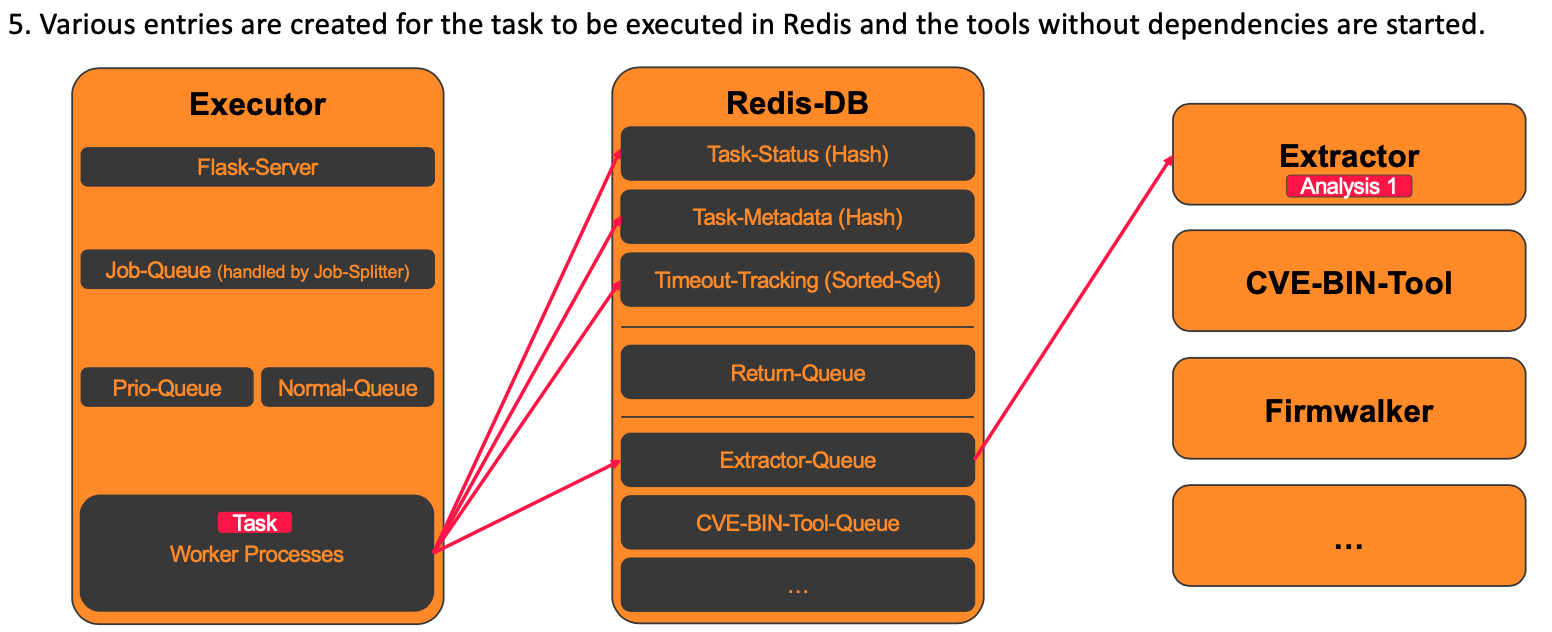
The following section shows the Python code that realises this.
redis_task_tracker.init_new_task(next_task.job_id,next_task.command,next_task.image_id,next_task.image_path, next_task.execution_nr, tools)
# The First round of execution in which all tools that have no further dependencies are executed.
for tool in tools:
if dependencies[tool] is None:
payload = {
"job": next_task.job_id,
"tool": tool,
"image_id": next_task.image_id,
"image_path": next_task.image_path,
"task": next_task.execution_nr,
"output_path" : output_path
}
# Create output path for analysis files
output_path = f'{payload["output_path"]}/output.txt'
os.makedirs(os.path.dirname(output_path), exist_ok=True)
queue = f"queue_{tool}"
redis_task_tracker.rpush(queue, payload)
print(f"[Executor] Data written to {queue}: {payload}", flush=True)
key = f"job{next_task.job_id}task{next_task.execution_nr}image{next_task.image_id}"
redis_task_tracker.set_tool_status(key, tool, "running")
Looking at our example for Task1, the status of the individual analysis tools at this point is as follows.
| Tool | Status |
|---|---|
| extractor | running |
| cve-bin-tool | new |
6. Feedback after an executed analysis
After an analysis tool has been executed, it transmits its results to the Executor via the return queue. Only the metadata of the analysis performed and the status (“success” or “failure”) are transferred. The Executor then checks whether it is a valid task and whether the execution of the analysis was successful.
####################################
###### 1. Prio Redis-Return-Q ######
####################################
data = redis_task_tracker.lpop("queue_return")
if data is not None:
payload = json.loads(data)
key = f'job{payload["job"]}task{payload["task"]}image{payload["image_id"]}'
print(f"[Executor] New message received in queue_return: {payload}", flush=True)
# Check whether there are still any entries for the key or whether it has already been deleted from Redis due to a timeout and failure
if not redis_task_tracker.key_exists(key):
print("[Executor] No matching key was found for the response to the executor.", flush=True)
continue
redis_task_tracker.set_tool_status(key, payload["tool"], payload["status"])
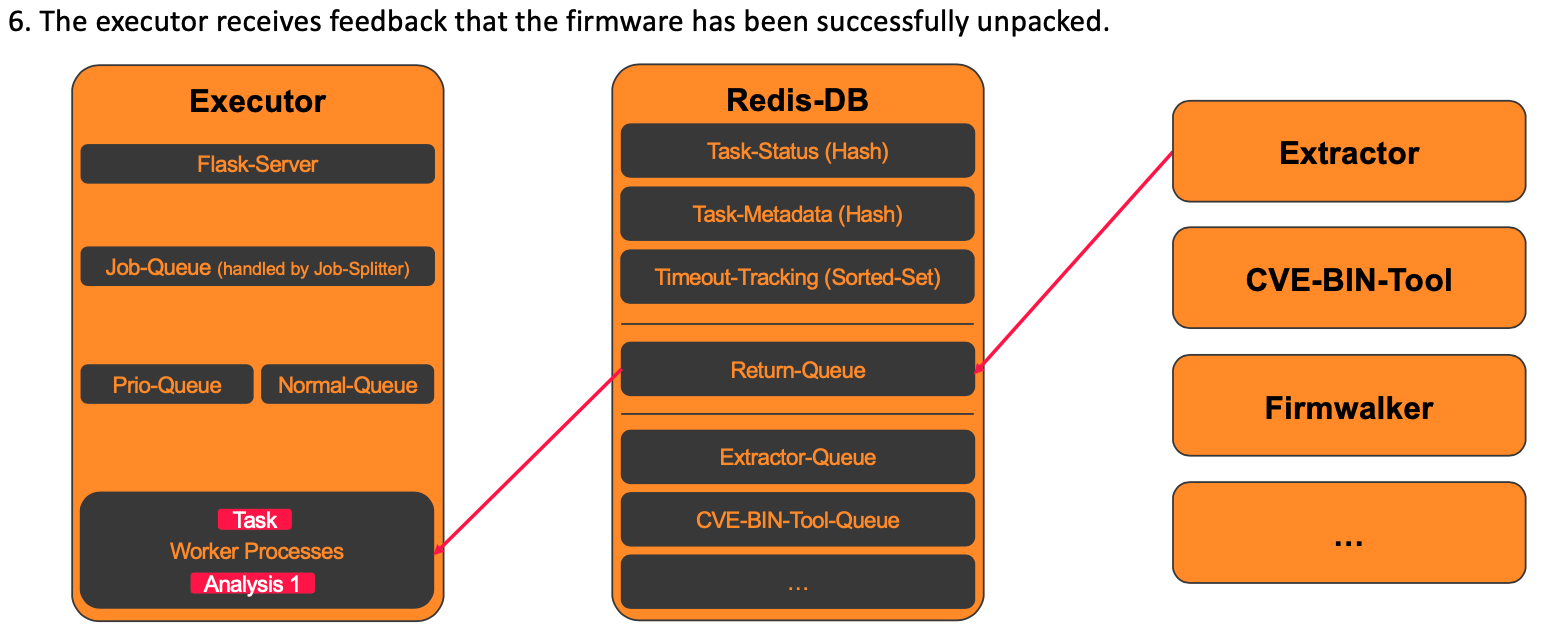
The status for Task1 looks as follows after the successful execution of the extractor:
| Tool | Status |
|---|---|
| extractor | success |
| cve-bin-tool | new |
7. Start of the tools, whose dependencies have been completely resolved
Once the Executor has verified the successful execution of a tool, it checks which further analyses can be executed based on the dependencies that have now been resolved.
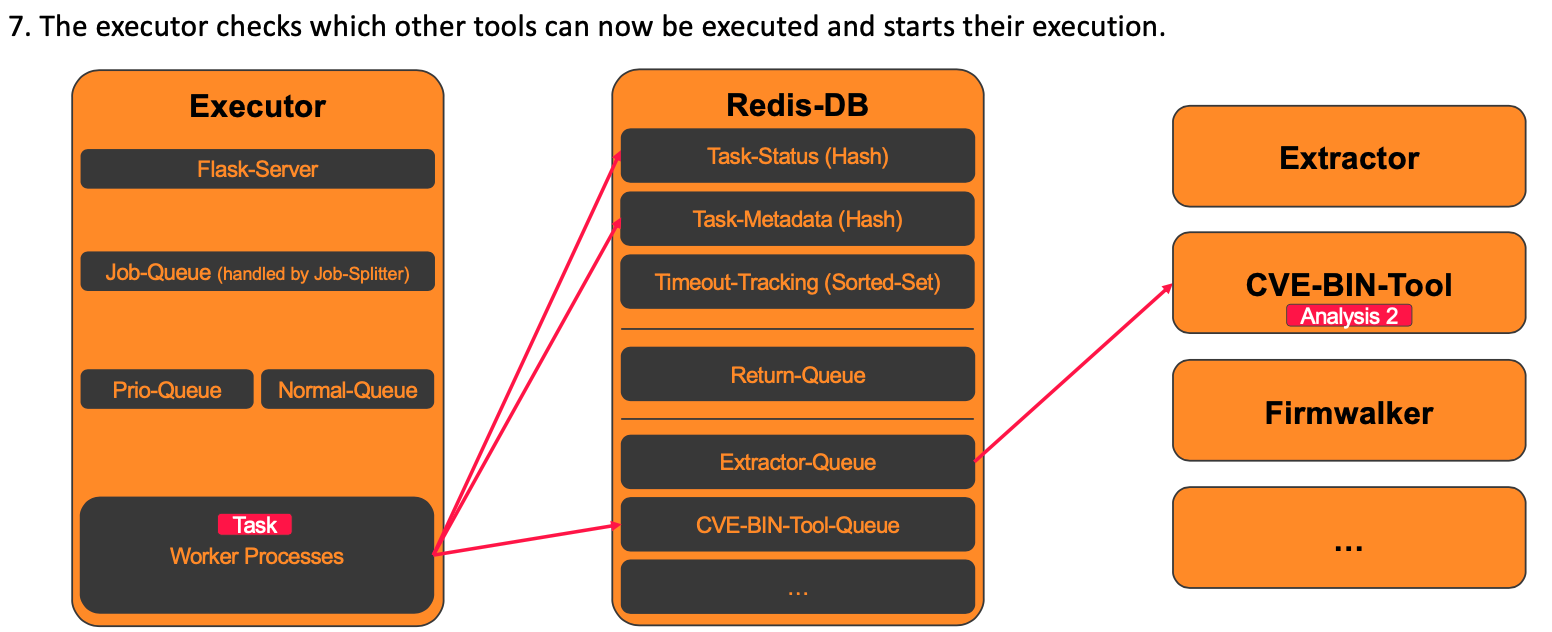
For each pending analysis tool, it checks whether all dependencies have now been resolved. If this is the case, the execution of this tool is started. The following Python code shows the exact implementation:
# Once an analysis tool has been successfully executed, the tools that depend on it can be started.
if payload["status"] == "success":
task_data = redis_task_tracker.get_task_status(key)
toggle_task_finished = True
for tool, status in task_data.items():
toggle_dependencies: bool = True
# Checks, whether all analyses have been performed, whether successful or failed.
if status != "success" and status != "failure":
toggle_task_finished = False
# Checks whether a tool has already been executed or is currently being executed
if status == "success" or status == "running" or status == "failure":
toggle_dependencies = False
# Checks whether an analysis tool still has open dependencies or whether they have all already been fulfilled.
elif dependencies[tool] is not None:
for dependency in dependencies[tool]:
if task_data[dependency] != "success":
toggle_dependencies : bool = False
if toggle_dependencies == True:
print(f'[Executor] All dependencies for {tool} have been resolved and {tool} has not yet been executed', flush=True)
payload_new = {
"job": payload["job"],
"tool": tool,
"image_id": payload["image_id"],
"image_path": payload["image_path"],
"task": payload["task"],
"output_path": payload["output_path"]
}
queue = f'queue_{tool}'
redis_task_tracker.rpush(queue, payload_new)
redis_task_tracker.set_tool_status(key, tool, "running")
# Checks whether all analyses of the task have been completed.
if toggle_task_finished == True:
save_final_task_stats(redis_task_tracker=redis_task_tracker, key=key, success=True, message="success")
Looking at our example for Task1 , the status of the individual analysis tools at this point is as follows.
| Tool | Status |
|---|---|
| extractor | success |
| cve-bin-tool | running |
8. Completed task
For each successful or failed analysis, the previously shown Python code is run through.
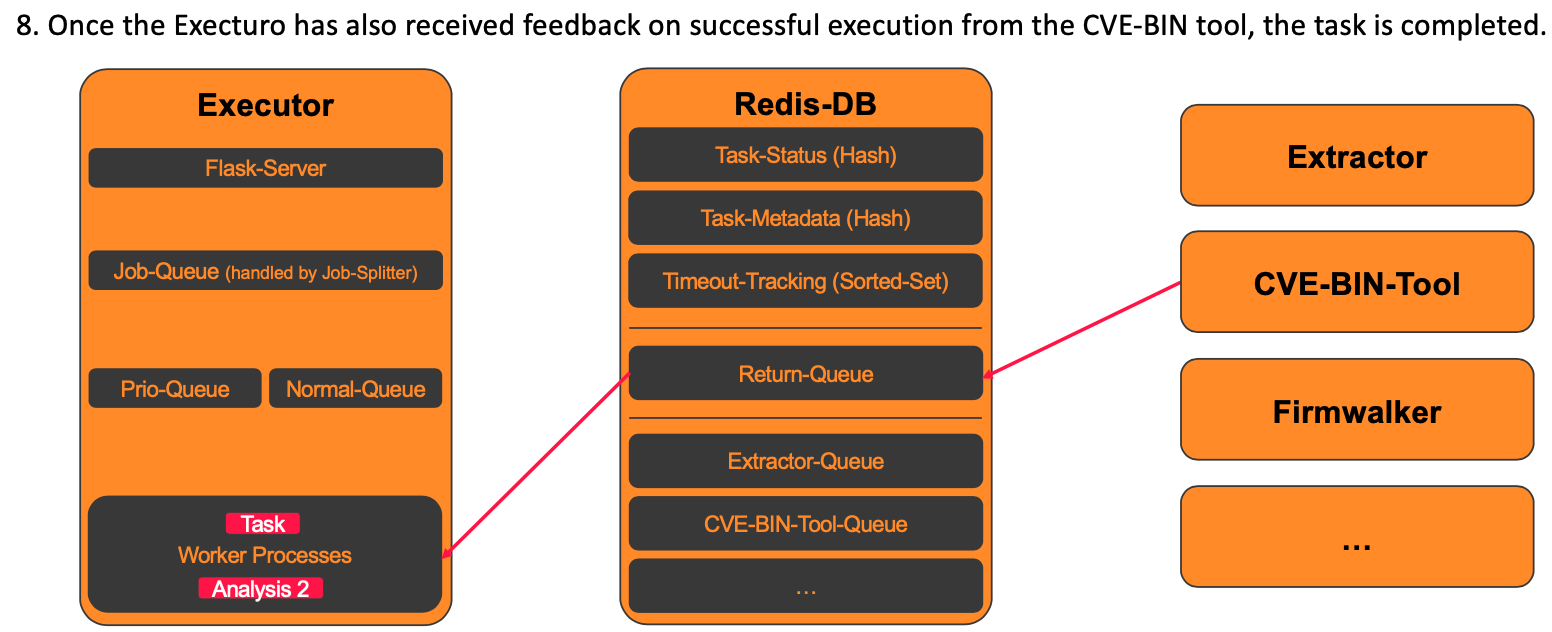
Looking at the example of Task1, both analysis tools have been executed successfully, resulting in the following status in the Redis-DB.
| Tool | Status |
|---|---|
| extractor | success |
| cve-bin-tool | success |
If, as in our example, all the analyses to be carried out have been successfully completed, the status of the task is saved in the database and the associated entries in Redis are deleted. When, on the other hand, an analysis fails and it is essential for the further processing of the task, the task is also terminated and noted as failed in the database.